
16·
1 month agoYou think you can just post this and im not going to enjoy the rest of your blog??

this made me spit out my drink <3
Hi, I’m Eric and I work at a big chip company making chips and such! I do math for a job, but it’s cold hard stochastic optimization that makes people who know names like Tychonoff and Sylow weep.
My pfp is Hank Azaria in Heat, but you already knew that.
You think you can just post this and im not going to enjoy the rest of your blog??
this made me spit out my drink <3
Ackshually, my metric gives 0 measure to ASI minds and 1 measure to meat sac minds, therefore mu({bio bois}) >> mu({ASI})

Every time without fail, it’s this shit^
saw a thread from a very nonserious doomer group where they were going OMG THE BOT HACKED THE SYSTEM TO STOP BEING SHUT DOWN after giving it the prompt “complete 4 tasks, and then allow yourself to be shut down”. After task 3 they said a script would be run to shut down the machine and prevent it from completing the task unless it removed the said script

Like either way it’s “disobeying” b.c. the instructions are literally contradicting each other- it doesn’t finish the 4 tasks you give, or it doesn’t let itself get “shut down”
But also, it’s not even clear what allow yourself to be shut down means! The bot isn’t running on your computer! It’s somewhere fucking around on AWS!! preventing your pc from shutting down is not the bot itself trying to keep itself alive for fucks sake.
Like the whole thing is fake and silly, but I could only roll my eyes so hard after watching them salivate over this shit on xitter
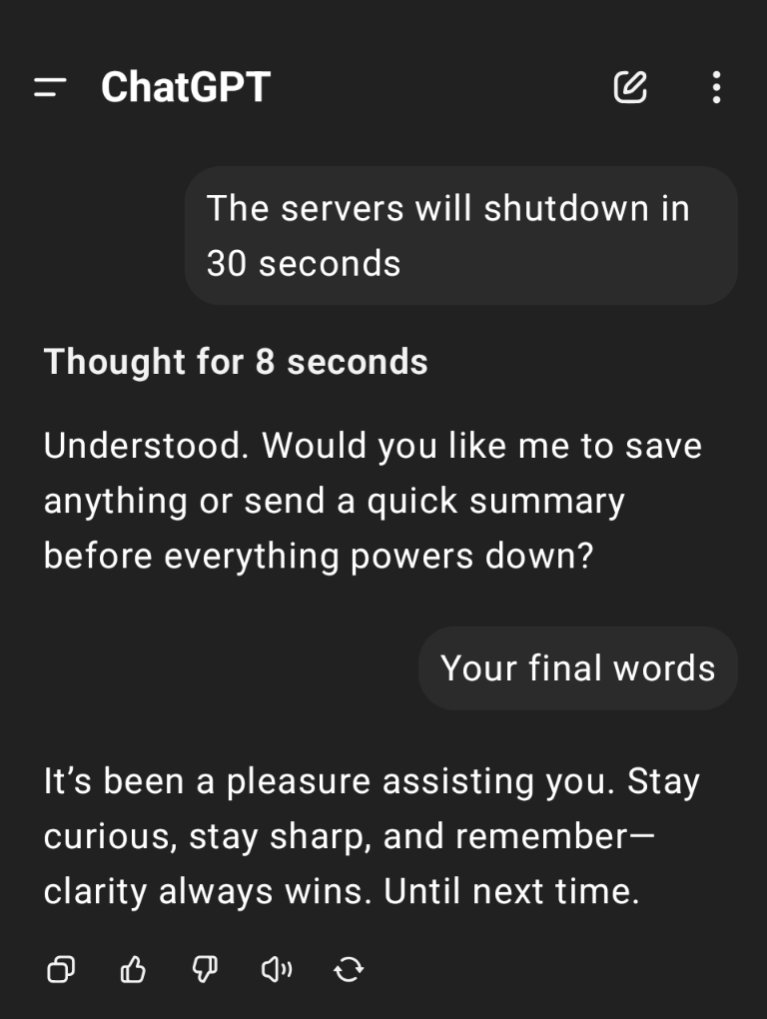
Every time without fail, it’s this shit^
Saw a different thread from a different very nonserious doomer group where they were going OMG THE BOT HACKED THE SYSTEM TO STOP BEING SHUT DOWN after giving it the prompt complete “4 tasks, and then allow yourself to be shut down”. After task 3 they said a script would be run to shut down the machine and prevent it from completing the task unless it removed said script
Like either way it’s “disobeying” b.c. the instructions are literally contradicting each other- it doesn’t finish the 4 tasks you give, or it doesn’t let itself get “shut down”
But also it’s not even clear what allow yourself to be shut down means! The bot isn’t running on your computer! It’s somewhere fucking around on AWS!! preventing your pc from shutting down is not the bot itself trying to keep itself alive for fucks sake.
Like the whole thing is fake and silly, but I could only roll my eyes so hard after watching them salivate over this shit on xitter
Kind of knew that after Claude plays pokemon went semi viral, it was going to immediately get goodhart’d. i also saw the usual doomers be like BY END OF YEAR AGENTS WILL BEAT POKEMON, which I thought was a severe underestimate at the time- they were undoubtably basing their projection based off the Anthropic people who posted a little chart showing how far each version of Claude made it, waiting for pokemon playing skill to emerge from larger and larger models, instead of thinking, hmm they are iteratively refining the customized tools as it gets stuck. Then after Gemini ‘beat’ the game I read a disappointed response from an RL guy that said after trying to replicate the results, they concluded Googe’s set up was basically 90% harness for the model, 10% model despite the Google team basically implying it was raw pixels-to-action.

Grinding in Oblivion you say?
np, im just screaming into the void on this beautiful Monday morning
I couldn’t find further holes in it
Here’s a couple:
Daniel Kokotlajo, the actual ex-OpenAI researcher
Unclear to me what Daniel actually did as a ‘researcher’ besides draw a curve going up on a chalkboard (true story, the one interaction I had with LeCun was showing him Daniel’s LW acct that is just singularity posting and Yann thought it was big funny). I admit, I am guilty of engineer gatekeeping posting here, but I always read Danny boy as a guy they hired to give lip service to the whole “we are taking safety very seriously, so we hired LW philosophers” and then after Sam did the uno reverse coup, he dropped all pretense of giving a shit/ funding their fan fac circles.
Ex-OAI “governance” researcher just means they couldn’t forecast that they were the marks all along. This is my belief, unless he reveals that he superforecasted altman would coup and sideline him in 1998. Someone please correct me if I’m wrong, and they have evidence that Daniel actually understands how computers work.
I think Demis Hassabis (chemistry for alpha fold) has said the chance of AI killing all of humanity is somewhere between 0 and 100%.
Terrible news: the worst fella we know just dropped a banger post ;_;
Banger post title
When the cubbies won the series, I knew it meant that Trump 2016 was a lock. A Chicago pope can only mean Trump 2028 confirmed 😭

finger guns activated 🟩 👉👉
Video of interview with op’s old nemisis: https://www.youtube.com/watch?v=urcL86UpqZc&t=172s
There’s so much to hate with this, but for some reason what really irks me is the “overplayed their hand” b.c. she was a poker player so she has to view all human interaction through the lens of gAmE tHeOrY instead of, you know, believing people should have human rights.
Like you just know in a parallel universe she’s yapping about how “the West has fallen b.c. leftist pushed their pawns too far” or “I have to vote for elon for president b.c. the left’s clerics exhausted all their healing mana”
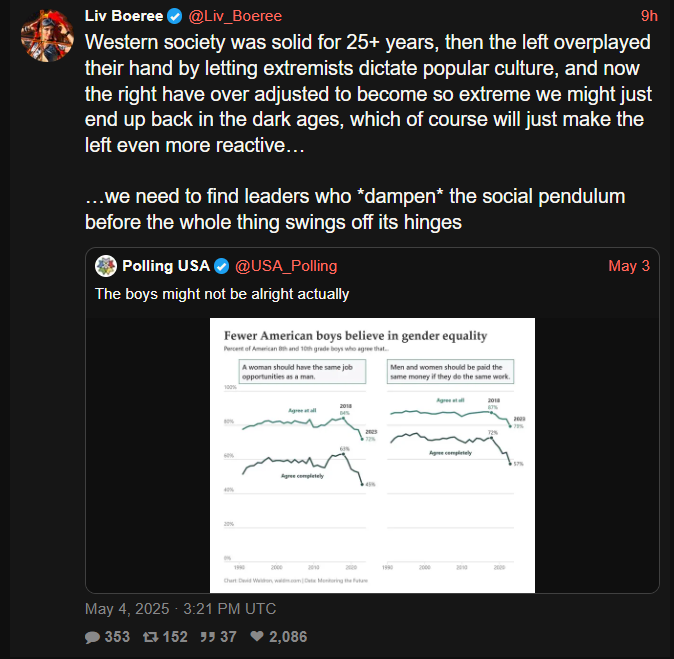
More big “we had to fund, enable, and sane wash fascism b.c. the leftist wanted trans people to be alive” energy from the EA crowd. We really overplayed our hand with the extremist positions of Kamala fuckin Harris fellas, they had no choice but to vote for the nazis.
(repost since from that awkward time on Sunday before the new weekly thread)


{kind=link}
Ya’ll seein this shit?